Concisely, the main features of the modeling framework within the OCHEM include:
- Support of regression and classification models
- Calculation of various molecular descriptors ranging from molecular fragments to quantum chemical descriptors. Both whole-molecule and per-atom descriptors are supported.
- Tracking of each compound from the training and validation sets
- Basic and detailed model statistics and evaluation of model performance on training and validation sets
- Assessment of applicability domain of the models and their prediction accuracy
- Pre-filtering of descriptors: manual selection, decorrelation filter, principal component analysis (PCA) based selection
- Various machine learning methods including both linear and non-linear approaches
- N-fold cross-validation and bagging validation of models
- Multi-learning: models can predict several properties simultaneously
- Combining data with different conditions of measurements and the data in different measurement units
- Distribution of calculations to an internal cluster of Linux and Mac computers
- Scalability and expendability for new descriptors and machine learning methods
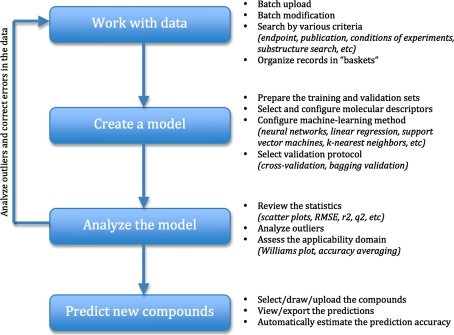
The steps of a typical QSAR research in the OCHEM system and the corresponding features are summarized in a diagram in the following figure: