OCHEM allows exploring the training set compounds that are in some way similar to the predicted compound (so called "prediction neighbors").
The prediction neighbors feature might be helpful for interpretation of a particular prediction.
Are there similar compounds in the training set? Are they active or inactive? These questions are addressed with the prediction neighbors feature.
To browse the neighbors of a particular prediction, simply click the "prediction neighbors" link as on the screenshot below:
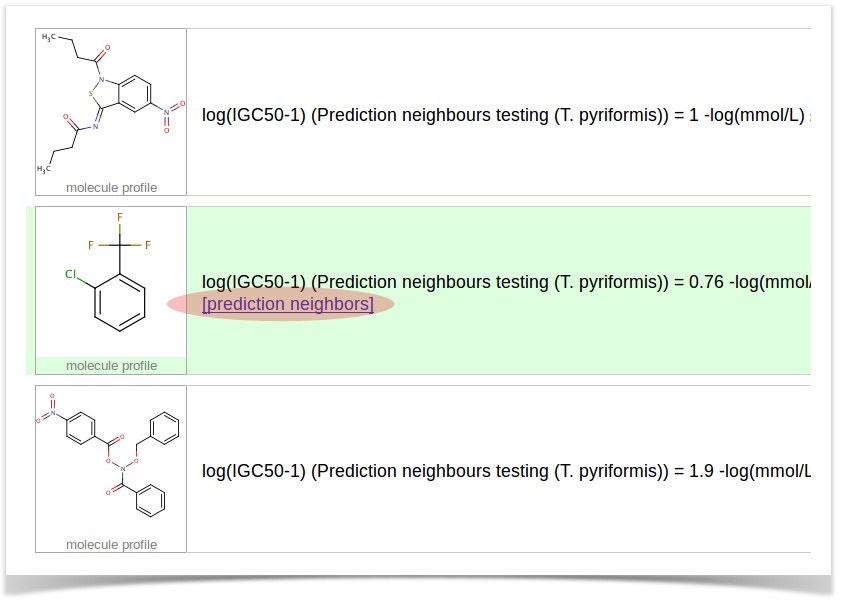
This will open the prediction neighbors explorer, which will show the similar structures from the training set and the detailed info (predictions, experimental values, etc.).
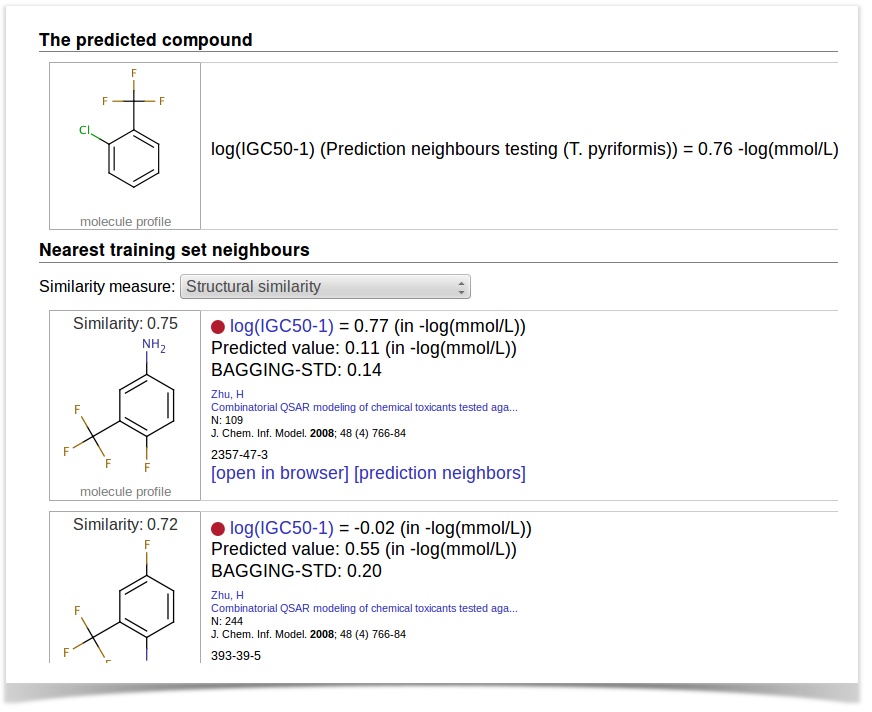
Similarity types
There are several ways to define the "nearest" neighbors from the training set. The most obvious one is structural similarity (e.g., using Tanimoto similarity). This is the default option.
If the model was built as an ensemble (that is, using bagging validation protocol, configured to store the individual ensemble predictions), the two other similarity measures are available:
- Correlation in the prediction space
- Euclidian distance in the prediction space